Your most valuable data is the hardest to use
You’re sitting on years of data your team can’t safely query.
You’ve spent years and a fortune building RWE, trial, registry and device data, yet most of it sits idle. Every question becomes a multi-month project in your biostatisticians’ backlog. Syno runs inside your environment, so your whole team can ask in plain language and get back analysis as auditable, executable code, with your experts reviewing results instead of rebuilding every analysis from scratch.
Runs in your environment · audit trail on every analysis · ISO 27001 (in progress) · built to support GDPR & EU AI Act compliance
The treasure and the queue
You own the most valuable dataset in your field. Most of it sits idle.
The questions are worth asking. The trouble is that each one is a multi-month project only your biostatisticians can run, and there are too few of them. The backlog grows while the data waits.
Syno opens that work to your whole team without loosening governance. Anyone can ask in plain language, and every analysis ships as inspectable, reproducible, auditable code. Your experts review the output instead of building it from scratch. The asset starts earning.
Why this is finally possible
The questions stayed locked up because conventional AI makes you send the data out.
That export is what turns every question into a months-long security and transfer review. Syno runs where your data already lives, so there is nothing to export and that review largely falls away. Your vendor security review still happens; the Trust Center is built to make it fast.
This is what turns a multi-month project into a question you ask on a Tuesday.
What you can finally ask
Questions that never got asked because they weren’t worth a ticket.
You can’t hire your way out of the queue. Unlimited seats let the whole organisation draw on the data without growing headcount.
Real-world evidence
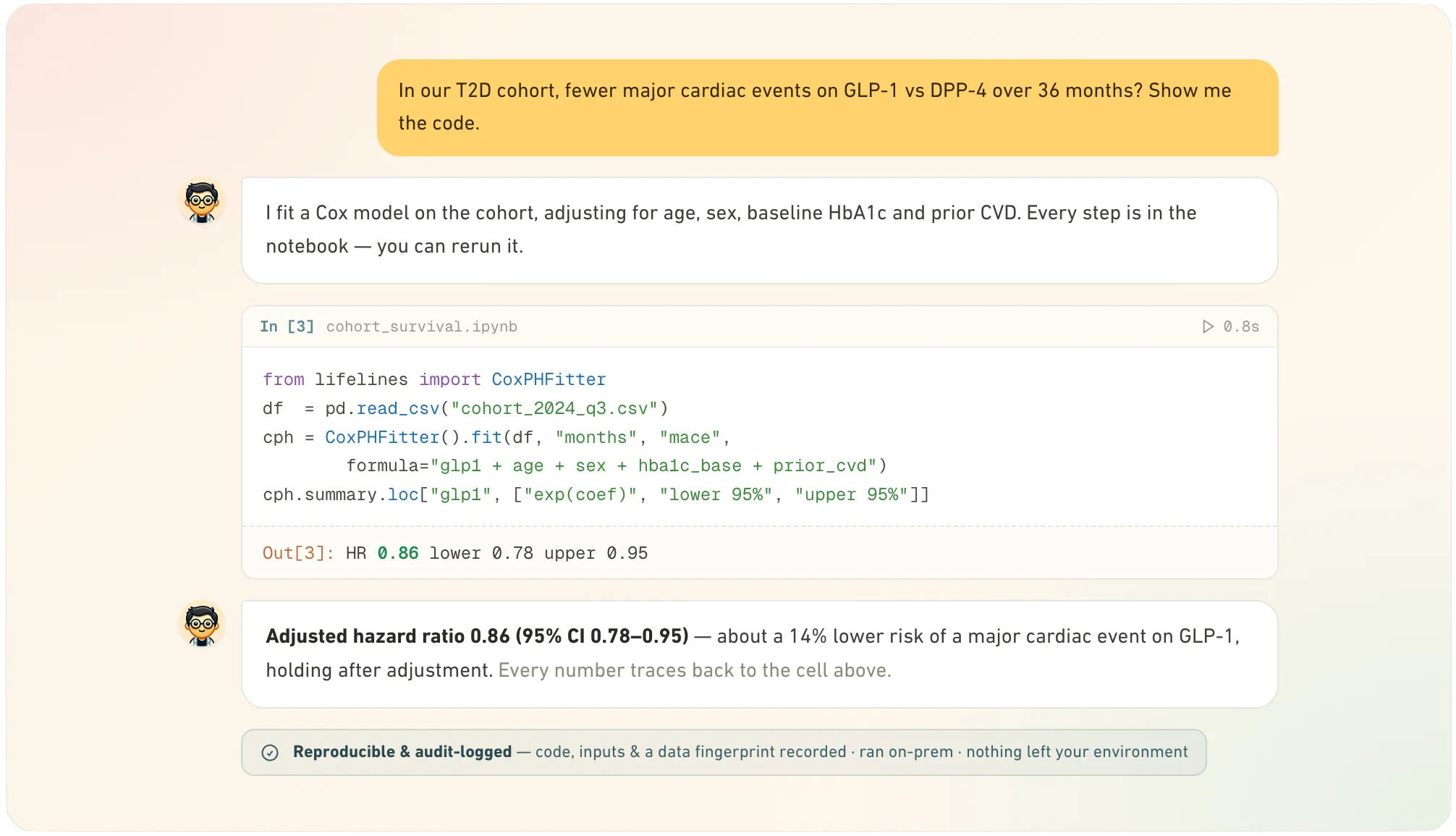
A comparative-effectiveness question across your RWE that would have been a multi-month analyst project. Frame it in plain language and get back reproducible code your team can inspect and rerun.
Safety & signal work
Cohort and signal exploration on your own pharmacovigilance and trial data, without an export that turns every question into a transfer review.
HEOR & payer evidence
Health-economic and outcomes analyses prepared faster, so the evidence for payers and HTA bodies is ready when the conversation is, rather than weeks behind it.
Registry & trial exploration
Open-ended exploration of registry and trial datasets — the work that never cleared the priority list.
See it on real work
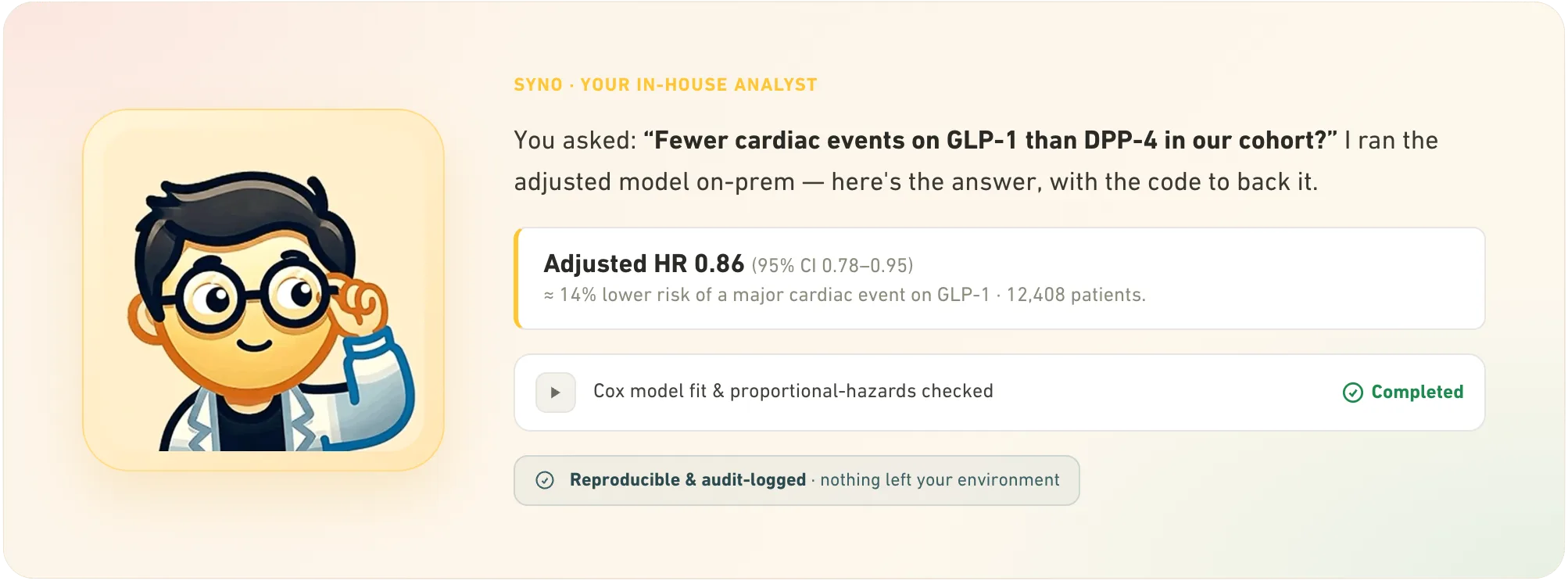
The answer comes with the code that produced it, and the audit trail beside it.
Trusted by research partners working on sensitive health data.
See our partners →Where Syno runs
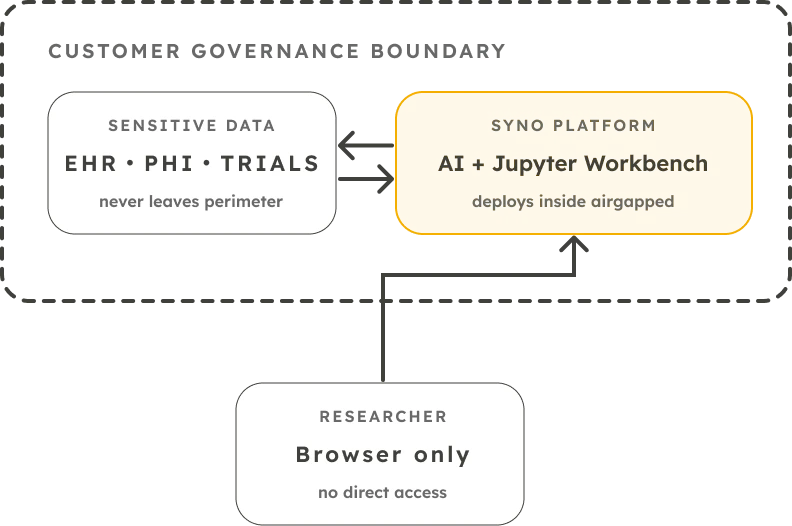
Be precise about where the AI runs. We are.
Identifiable health data uses one of these three modes. A separate Managed-Global mode exists for non-identifiable, exploratory data only.
Managed-EU
Runs on EU-resident managed infrastructure. A named EU sub-processor (disclosed in the Trust Center) handles inference; your data is never used to train models.
Self-hosted
Your own cloud or VPC, your own or open-source models. Fully in-boundary, so nothing leaves your environment.
Air-gapped
On-premises, with no outbound network connection at all.
Every outbound connection and inference location is drawn out, per mode, in the Trust Center.
The fastest way to judge it is to use it.
The Proof Pilot
Prove it on one question from your team’s backlog.
The Proof Pilot — €9,999, fixed.
Two months. Your own data, integrated into a dedicated Syno instance in our secure EU cloud. One question, a set end date, and a real finding your team keeps. The full €9,999 credits to your subscription if you continue, and you keep every result either way.
Production sits below the fully-loaded cost of one biostatistician, and your €9,999 credits to it in full. The pilot runs on de-identified or synthetic data, and the DPA and DPIA review run alongside it, so there’s no second gauntlet at production.
A pilot proves capability and fit; formal validation is a supported step that runs with you, not a fresh approval cycle.
The honest ROI
The payoff is internal. Here is how it adds up, with the honest caveats.
Start with a question a VP can repeat: how many analyses does your team defer or decline each quarter for lack of capacity?
The anchor: the subscription sits below the fully-loaded cost of one biostatistician.
Work you can finally take on
The analyses your team couldn’t reach before, now within reach without hiring.
Outside spend, offset
A capable in-house platform offsets external data-science spend. Syno frees your team; it doesn’t replace your trusted partners.
Faster time-to-evidence
The analysis layer moves faster for payers and regulators. That speed is in the analysis itself, not in your trial or regulatory timelines.
This isn’t a “more trials per year” story. That is a CRO’s math, and this is a pharma page. See the CRO page →
Your team’s methods, made reusable
Encode your team’s expertise once. Let your whole org use it safely, on your own data, with the same audit trail.
Your agents are your IP. Single-tenant, never reused for another customer, never used to train shared models. Exportable in open formats, runnable in your own environment, and inspectable and editable by your team.
They’re version-pinned, so a validated workflow stays validated until you change it. Any hands-on help is a fixed-price method-encoding sprint, never an open-ended services contract.
Your agents, your IP, yours to keep.
- ✓Single-tenant, never reused for another customer
- ✓Exportable in open formats, runnable in your environment
- ✓Inspectable and editable by your own team
- ✓Version-pinned, so validated stays validated until you change it
Before you ask
The questions your IT, DPO and QA teams will raise.
How is this different from ChatGPT?
In short: where it runs and what it leaves behind. Syno runs where your data lives and ships auditable code, not just an answer.
See the full comparison →A Trust Center your team can open today
Data-flow diagrams, compliance posture, the sub-processor list, and the documents your security review needs.
Open the Trust Center →Frequently asked
Where do the models actually run?
You choose the mode. In Managed-EU, inference runs on EU-resident infrastructure through a named sub-processor and is never used to train models. In self-hosted and air-gapped modes, everything runs inside your boundary. The per-mode data-flow diagrams live in the Trust Center.
Does it fit our GxP and validation requirements?
Every analysis ships as inspectable, reproducible code with a full audit trail, designed to support validation and regulatory-submission workflows. Ad-hoc analyses are reproducible too: the generated code reruns deterministically on the same data. Validation is a supported step that runs alongside the pilot, not a second approval cycle.
What will our DPO and QA teams need?
A ready-to-sign DPA, a DPIA starter, the sub-processor list, and our no-training-on-your-data contractual commitment. All of it is available through the Trust Center, the gated items under NDA.
Ask the question that’s been waiting.
Start with the live demo, bring in your IT and compliance teams, or prove it on one question from the backlog.