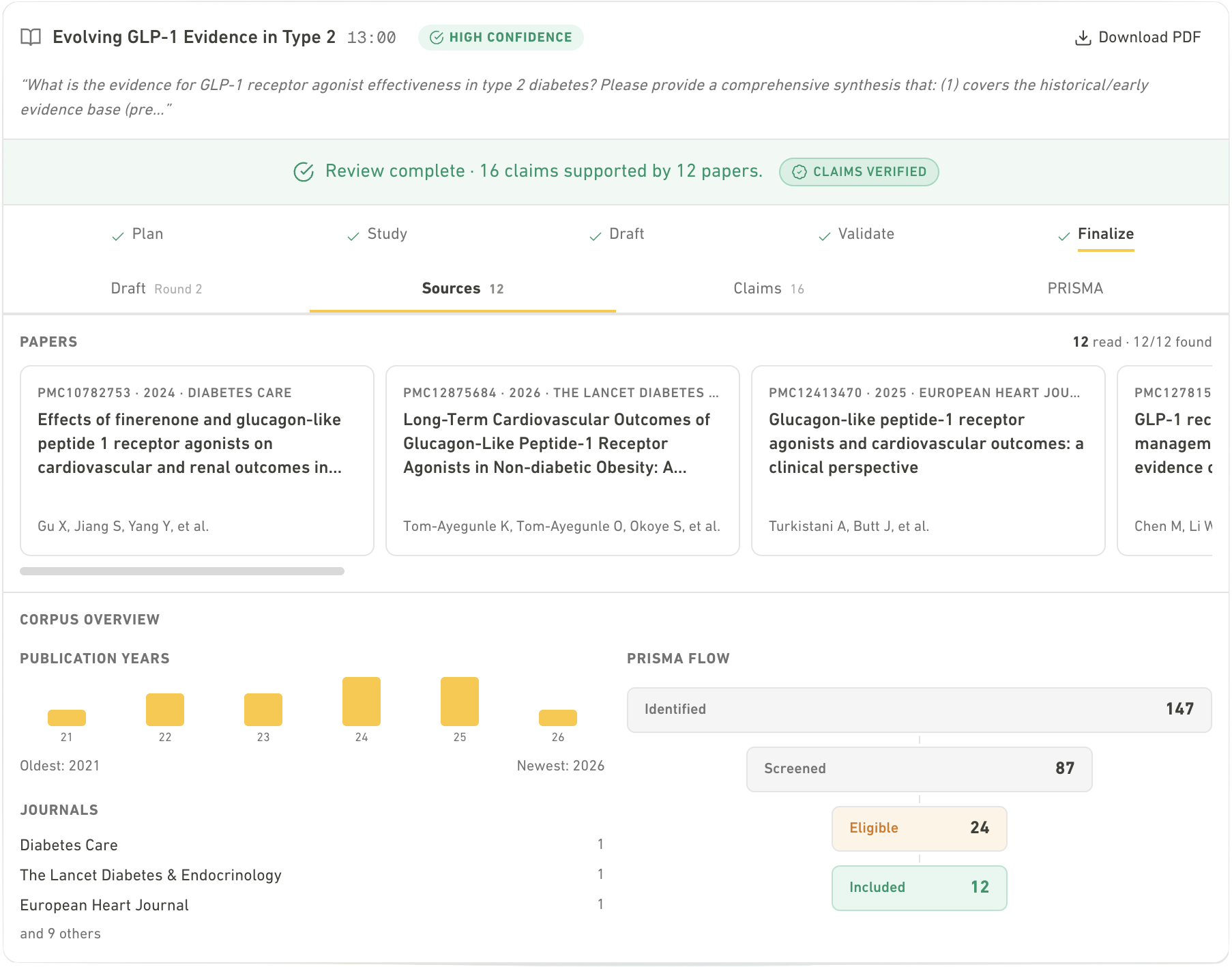
Part of the Syno platform · Literature review
Reviews whose every claim you can verify in seconds rather than hours.
Syno is a biomedical literature-review agent that treats citation faithfulness as a property to measure rather than assert. Every claim is grounded in a retrieved passage and judged against the cited paper on independent axes: population, numerics, outcome, recency. Each verdict carries the exact passage it was scored against, so you can trace any sentence back to the paragraph that justifies it.
Syno is built for reviews a human can check claim by claim, not for raw speed over a human reviewer.
The citation crisis
The papers are real. The sentences built around them are wrong.
The field trained itself to watch for fabricated citations. Peer-reviewed audits now show the dominant failure is subtler. The DOI resolves and the authors check out, yet the sentence built around the paper overstates it, misreports its population, or reverses what it found.
47–50%
of references from leading generalist deep-research tools carried fabricated authors or titles on medical prompts.
JMIR 2026 · Wong, Ong, Merle & Keane
>50%
of the strongest tool’s cited statements still contained at least one subtle inaccuracy or misrepresentation of the source.
OpenAI Deep Research, same evaluation
75–83%
the per-claim accuracy careful human reviewers reach. AI errors belong against that band, not against zero.
Baethge & Jergas meta-analysis and others
Design principles
We measure citation faithfulness rather than assert it.
Six principles, each answering a documented failure mode and grounded in established evidence-synthesis methodology.
Closes citation fabrication
Retrieval-first grounding
No claim enters the output without a retrieved passage. Planning, drafting, and validation all draw from one fixed evidence set, fingerprinted at retrieval. The writer cannot name a paper that isn’t in it.
Catches misinterpretation
Per-axis judgment
Each (claim, paper) pair is judged on four independent axes: population, numerics, outcome, recency. A paper can entail a claim’s direction and still fail the population check. That mismatch is preserved through aggregation and surfaced to the writer.
Displaces vote-counting
Quality-weighted aggregation
Meta-analyses and randomised trials carry the most weight, case series and mechanistic work the least. Weights are bounded so no single study overwhelms a contradicting body of evidence: a 50-patient pilot is not one vote against a 5,000-patient trial.
Surfaces suppressed dissent
Cross-paper dissent check
A separate pass targets every grounded claim that cites just one paper, pulls top uncited candidates from the same round, and demotes the claim if a supermajority contradict it. Silence is not counted as disagreement.
Surfaces contestation
Multi-tier, cross-family escalation
When a first-pass verdict is low-confidence or contested, the same input is re-judged by a deeper model from a different family and vendor. The escalation is recorded rather than averaged away, and because the fallback chain crosses vendors, a single-provider outage falls back to a different family instead of degrading the output.
Makes reviews reproducible
Auditable, version-stamped verdicts
Every verdict carries cited paper IDs, a passage anchor, per-axis judgments, escalation history, and a policy version. Change the scoring regime and the version bumps; old verdicts are re-judged on the next run, not reused.
Per-claim trust
Every claim carries its own verdict.
A 7,000-word review holds hundreds of claims of widely varying defensibility. An overall “trust me” score tells a reader nothing about which paragraph to scrutinise. Syno emits a verdict for each claim, with the per-axis judgments that produced it and a passage anchor a reader can open in seconds.

Grounded
Cited papers directly support the claim along all relevant axes; the cross-paper check passes.
Weakly grounded
Support exists but is qualified: a broader population, a surrogate outcome, or a single small cohort.
Not grounded
No retrieved paper substantively supports the claim.
Contradicted
At least one cited paper actively conflicts with the claim along a substantive axis.
Literature disagrees
Multiple credible papers in the evidence set point in opposing directions; dissent is preserved, with its temporal direction.
Abstain (scope-rejected)
The claim falls outside the locked scope or is trivially un-evaluable; not pursued.
Escalation-dropped
The escalation budget was spent before a verdict resolved; kept distinct from scope rejection in the audit trail.
How a review gets built
Seven phases, each one producing an artefact you can reproduce from its inputs alone.
Planning
The question is decomposed into a research plan: PICO framing where it applies, inclusion criteria, and the review posture (systematic, scoping, or narrative). The plan is recorded alongside the active policy version.
Retrieval
A curated biomedical corpus (PMID, PMCID, DOI, plus arXiv preprints) is queried with hybrid dense-plus-lexical search. Every run records a cryptographic fingerprint of the corpus, so a reader can confirm two runs hit the same evidence base, and dedicated slots keep dissenting evidence from being filtered out.
Study
Each retained paper becomes a structured record (study design, population, sample size when stated) plus a faithful summary. Both feed drafting and validation.
Drafting
A long-context model composes the prose, tagging every substantive claim with supporting paper IDs from the fixed set. The writer cannot cite a paper outside it.
Per-claim validation
Prose is decomposed into atomic claims. Each is graded per-axis, weight-aggregated, run through the dissent check, and escalated when contested, with a wall-clock budget on every call so a stuck escalation can’t consume the whole compute budget.
Revision
The writer sees structured verdicts, reframing hints, and concrete replacement citations from the same evidence set. Already-grounded claims are held stable, so verified work isn’t re-judged round after round.
Audit output
The review ships with the prose and everything needed to check it: the per-claim verdict record, passage anchors, the policy version, the corpus fingerprint, a PRISMA 2020 four-stage flow, and a provenance-carrying bibliography.
External benchmark · diabetes
One topic, one run per tool, fully reproducible from the published data.
The primary endpoint
+18.8 pts per-claim numeric fidelity over Elicit, the strongest peer.
On ten pre-registered diabetes review questions, graded by a three-model panel across two families, Syno led Elicit by a per-question mean of +18.8 percentage points (95% CI [+9.4, +28.2]), and was ahead in 9 of 10 questions. The lead held across every judge subset we cut the data by.
Citation existence: the trust floor
The three purpose-built tools cluster at the top. The generalist agent is the outlier: only 69.2% of its citations resolve to an indexed scientific paper.
Honest scope: diabetes only, one capture per tool, graded by an external model panel rather than human experts. Syno was graded on full text; abstract-only tools on abstracts, the evidence base each one actually serves in production. We read this as one corroborating data point rather than the thesis.
Download the data package: every question, every raw verdict →
Methodological lineage
We build on the evidence-synthesis canon, and name every standard.
A review agent that ignores these standards is closer to a search-results summariser than to a literature-review instrument.
Prove every sentence in your next review.
Run a citation-faithful review on your own questions, or book a demo and watch a claim resolve back to the passage that supports it.
Re-run the same questions over the same evidence set and policy version, and you get back the same conclusions.